(You can read this post in english)
Em Ciência dos Dados, qual processo podemos utilizar? Como, a partir de uma ou mais fontes de dados, podemos extrair padrões escondidos e construir modelos preditivos? Apesar do termo Ciência dos Dados (do original Data Science, em inglês) ser relativamente novo, a Ciência da Computação já se preocupava com esse tipo de problema há pelo menos duas décadas. Um trabalho acadêmico bastante importante nesse sentido foi o artigo publicado por Fayyad et al., em 1996: “From Data Mining to Knowledge Discovery in Databases” [1]. Os autores inaugurariam o processo então batizado de Descoberta de Conhecimento em Base de Dados (do inglês Knowledge Discovery in Databases — KDD), como pode ser visto na figura abaixo:
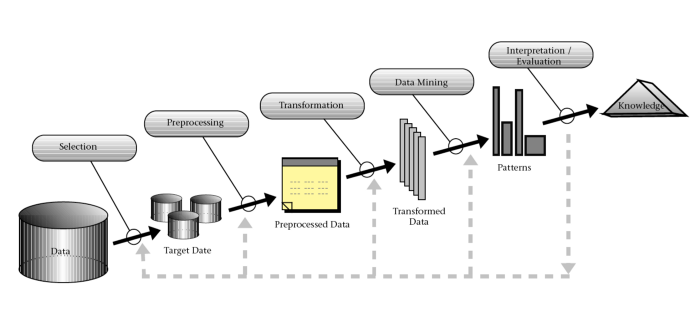
Como explicitado na figura, o KDD é composto por cinco etapas, a saber:
Seleção: os dados são selecionados de uma ou mais fontes de dados, a partir de um entendimento do negócio em alto nível.
Pré-processamento: os dados são sanitizados, incluindo limpeza de dados, eliminação de inconsistências, tratamento de dados faltantes etc.
Transformação: os dados são transformados de acordo com a fase posterior, onde os padrões escondidos são realmente extraídos. Por exemplo, essa etapa pode incluir redução de dimensionalidade e mudanças de codificação.
Mineração de Dados: após pré-processamento e transformação dos dados, modelos preditivos ou de sumarização são construídos a partir da área da Inteligência Artificial conhecida como Aprendizagem de Máquinas ou mesmo da Estatística. É aqui onde os padrões escondidos e valiosos são encontrados.
Interpretação/Avaliação: nessa etapa, os padrões escondidos e os modelos inteligentes são avaliados e interpretados, normalmente em parceria com os especialistas do domínio e com o cliente.
Interessante notar que uma das etapas do KDD possui um termo bastante conhecido (e já calejado) em TI: a mineração de dados. Ao longo dos anos, mineração de dados se confundiu com o processo KDD como um todo, quando na verdade aquele é apenas uma fase deste. Também é curioso como, em uma área tão dinâmica como a Computação, os termos precisam se reinventar. Se Mineração de Dados soa hoje antiquado, a sua ideia pouco difere dos mais badalados e modernos termos como Data Science ou Analytics.
O KDD provê uma visão intuitiva e geral do esquema de extração de conhecimento. Entretanto, o processo promove uma falsa ideia de que as suas etapas devem ser seguidas linearmente, o que definitivamente não é verdade. Por exemplo, a seleção e o pré-processamento dos dados andam de mãos dadas. Para a mineração, é essencial que os dados estejam devidamente transformados.
Nesse sentido, podemos entender a motivação da criação de um outro processo relacionado, chamado CRISP-DM (do inglês CRoss-Industry Standard Process for Data Mining). O CRISP-DM surgiu também em 1996 como um processo aberto de extração de conhecimento em dados, proposto por um consórcio inicialmente composto por cinco grandes empresas [2]. Como pode ser visto na figura abaixo, o CRISP-DM indica de maneira mais adequada como suas diversas etapas se relacionam.
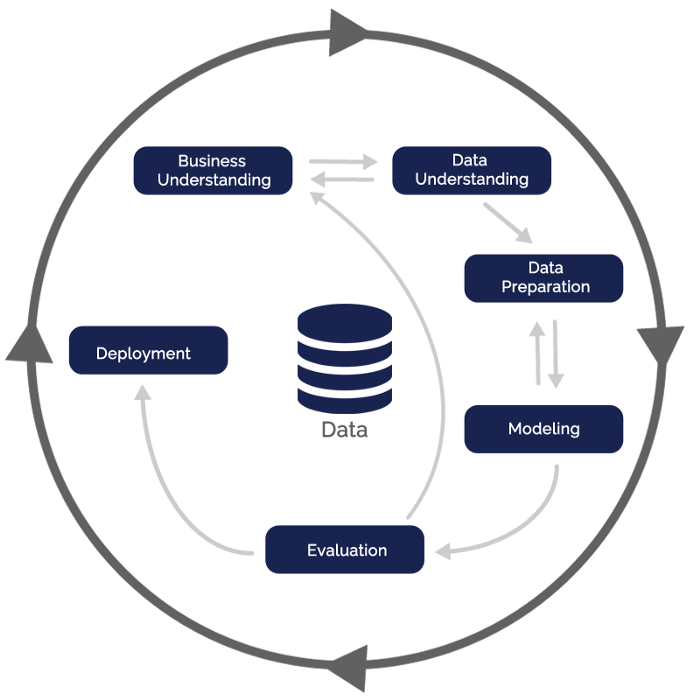
Além de incluir ciclos de feedback em suas diversas fases, o CRISP-DM difere do KDD principalmente em dois aspectos. Primeiro, há uma etapa clara e específica para o importante estágio de entendimento do negócio. É nessa fase que as perguntas são feitas, que o cliente explicita suas necessidades. O processo transita entre o entendimento do negócio e o entendimento dos dados, indicando, por exemplo, que o cliente é de crucial importância no início do processo. Quando o modelo é finalmente construído e avaliado, as atividades podem voltar para o estágio inicial, buscando sempre o desempenho desejado.
Outra importante perspectiva oferecida pelo CRISP-DM é a presença de uma etapa de deployment. É nesse estágio que o modelo construído e avaliado pelos especialistas no domínio e/ou pelo cliente é finalmente incorporado em um sistema de apoio à decisão. A análise de dados transforma-se, finalmente, em engenharia de software.
Em suma, tanto o KDD como o CRISP-DM podem ser utilizados como guias para o processo de extração de conhecimento em bases de dados. Entretanto, o CRISP-DM mostra-se mais completo e evidencia a flexibilidade das etapas, indicando que as atividades transitam entre diversos estágios em prol do objetivo final.
[1] https://www.aaai.org/ojs/index.php/aimagazine/article/viewFile/1230/1131, acessado em 12/09/2020
[2] https://en.wikipedia.org/wiki/Cross-industry_standard_process_for_data_mining, acessado em 12/09/2020
Publicado originalmente em: https://medium.com/@atenorios/processos-em-ci%C3%AAncia-dos-dados-62cbd6402a20