(You can read this post in english)
Segundo a Wikipedia, o Estado da Arte “é o nível mais alto de desenvolvimento, seja de um aparelho, de uma técnica ou de uma área científica, alcançado em um tempo definido”.
Com o crescente interesse em Inteligência Artificial e Data Science nos últimos anos, o número de pesquisas e aplicações nessas áreas aumentou exponencialmente. Seja você um pesquisador e/ou professor, um profissional de TI interessado nesse campo de estudo ou mesmo um curioso desejando aprender mais sobre o que podemos fazer com um sistema inteligente, a tarefa de entender as tendências e últimos avanços nessas áreas do conhecimento em publicações acadêmicas é bastante árdua.
Há algum tempo tenho tentado organizar uma forma de sistematicamente acompanhar o Estado da Arte em campos específicos de Data Science e na Inteligência Artificial de maneira geral. Esse artigo contempla algumas ferramentas para alcançar esse fim. Via de regra, considero o trabalho de “ficar informado” como sendo acompanhar as principais publicações e se aprofundar naquelas que despertam um maior interesse. É virtualmente impossível ler e entender tudo que é publicado. O que se pode fazer, inicialmente, é ler o abstract da publicação com o título que desperte sua atenção (pelo problema que resolve ou pelos algoritmos, técnicas e tecnologias que utiliza) e, caso o interesse persista, fazer um “skimming”. Skimming, cuja tradução em português me escapa, consiste em “passar a vista” no texto. Em um artigo acadêmico, passar a vista presume a leitura (às vezes dinâmica) da introdução e da conclusão. Se após esses passos o interesse continua, você pode colocar o artigo na lista de trabalhos a serem lidos e estudados. Abaixo, as ferramentas que utilizo com o objetivo de acompanhar o estado da arte em IA e campos correlatos. Algumas delas servem para qualquer área da ciência, enquanto que outras são específicas.
arXiv
O arXiv (pronuncia-se em inglês “arquive”) é um repositório de e-prints (pré-prints eletrônicos) abertos nas mais variadas áreas da ciência. Atualmente a plataforma reúne trabalhos em Física, Matemática, Ciência da Computação, Biologia Quantitativa, Finanças Quantitativa, Estatística, Engenharia Elétrica e Economia. Mas o que é um e-print? São artigos que não passaram (ainda) por uma rigorosa revisão por pares, como acontece numa revista científica tradicional. Porém, uma equipe de moderadores de cada área faz uma revisão básica para categorização e eliminação de trabalhos não científicos. A maioria desses trabalhos eventualmente serão revisados e publicados em uma publicação acadêmica. Além disso, os e-prints são endorsados na própria plataforma. Alguns artigos seminais e influentes, entretanto, foram publicados apenas no arXiv.
Cada uma das grandes áreas são divididas em um bom número de subcampos. Abaixo, os subcampos disponíveis em Ciência da Computação.

Um ponto controverso no arXiv é o considerável número de trabalhos submetidos diariamente. Por exemplo, no dia em que estou escrevendo essa postagem, há 106 artigos apenas no campo de Machine Learning. Como acompanhar tudo isso é quase que impraticável, podemos usar alguns atalhos para acessar os artigos supostamente mais importantes. Esse é o trabalho do arXiv Sanity (nome sugestivo, por sinal). Baseado em feedbacks dos usuários, o arXiv Sanity é capaz de apresentar com um maior destaque os trabalhos mais bem avaliados, além de mostrar de maneira mais amigável imagens do artigo e seus respectivos resumos. Adicionalmente, desde que você esteja logado, é possível adicionar alguns artigos na sua lista de leitura, o que possibilita recomendações da própria plataforma. O vídeo explicativo do autor esclarece mais algumas features. Importante salientar que o arXiv Sanity é focado apenas na área de IA e Ciência de Dados.
DeepAI
Aqui as coisas ficam mais simples. O DeepAi é um site agregador de artigos influentes e notícias da mídia tradicional quando o assunto é Inteligência Artificial. Como pode ser visto na imagem abaixo, baseado no feedback dos usuários, o site mostra notícias e artigos acadêmicos que estão em destaque nos últimos dias.
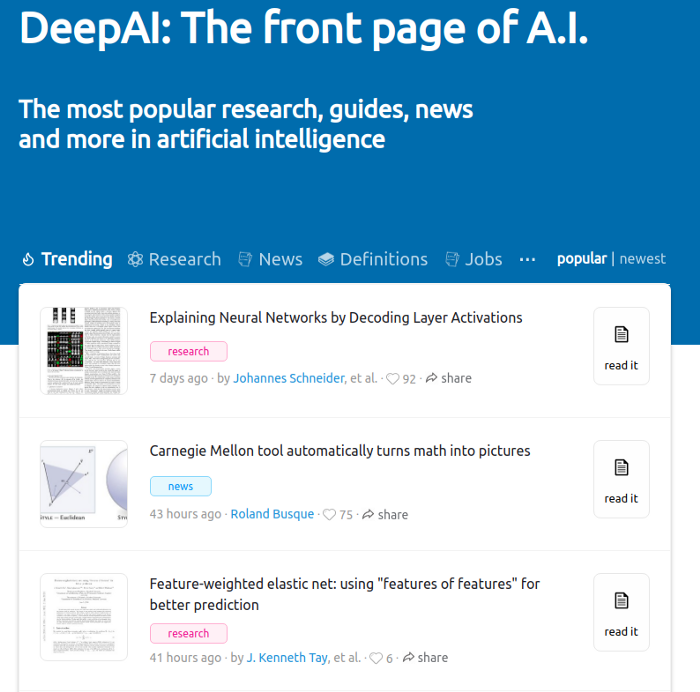
Uma seção que eu considero importante é aba de “Definições”. Nela, é possível encontrar explicações concisas sobre tópicos importantes em IA, como o Teorema de Bayes ou o básico de redes neurais.
Papers with Code
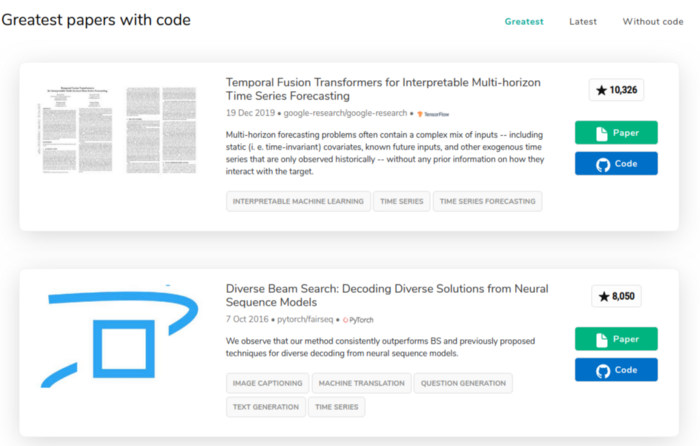
O nome Papers with Code é sugestivo. O site, também a partir do feedback dos próprios usuários, indica artigos acadêmicos nos mais variados subcampos de Data Science (e também em alguns tópicos adicionais), preferencialmente com código-fonte e base de dados disponíveis. A plataforma também agrega alguns placares com o desempenho de variadas soluções para um mesmo problema. Abaixo, dois trabalhos da seção “séries temporais”.
Mendeley
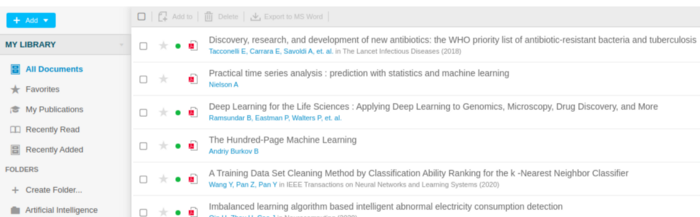
O Mendeley é o que eu chamo de rede social dos pesquisadores. Dentre outras features, a plataforma inclui a criação de um perfil, listagem de artigos publicados, inclusão de grupos de pesquisa e listagem de vagas de empregos relacionados. O que interessa para essa postagem é a aba de sugestão. Quando o usuário adiciona alguns artigos (em formato PDF) na seção “library”, como um repositório próprio de leitura, a plataforma passa a sugerir trabalhos semelhantes. Eu tenho usado o Mendely para organizar a pilha de leituras. Dá pra fazer isso tanto na versão web como também no app para dispositivos móveis. Abaixo, o estado atual da minha “biblioteca”.
Por sinal, me segue lá.
Revistas Científicas
Por fim, se você está mais habituado à linguagem e modus operandi acadêmico, talvez valha a pena visitar o próprio site das revistas científicas da área. Aqui as coisas ficam um pouco mais complicadas de se organizar, pois o número de publicações renomadas é alto e bem diverso. Mas de vez em quando acho que vale a pena dar uma olhada. Eu costumo olhar o site da IEEE Transactions on Neural Networks and Learning Systems e da Neurocomputing. Existem muitas outras, aqui vai da preferência de cada um. Se for um artigo importante, provavelmente o trabalho vai aparecer nas plataformas apresentadas anteriormente. Importante notar que, a não ser que você esteja na rede de uma universidade, não será possível baixar o PDF por meios tradicionais.
Conclusão
Essa postagem teve por objetivo sugerir formas e plataformas para acompanhar os principais e mais recentes trabalhos em Inteligência Artificial e Data Science. Muitas vezes eu não dou conta de acompanhar esse volume vertiginoso de informações, mas esses são os métodos que eu uso para tentar ficar informado. Conhece mais algum site nesse sentido? Compartilha aí com a gente.