(Você pode ler esse post em português)
According to Wikipedia, the State of the Art refers to “to the highest level of general development, as of a device, technique, or scientific field achieved at a particular time”.
With the growing interest in Artificial Intelligence and Data Science in the last years, the number of researches and applications in these fields has expanded exponentially. Being a researcher, a professor, an IT professional, or even a curious practitioner eager to learn more about it, the task of understanding the trends and the latest advancements in these fields in academic publications is difficult enough.
It’s been a while since I have tried to summarize a systematic way to follow the state of art in Data Science and general Artificial Intelligence. This post contemplates a few tools to reach this goal. In particular, I consider the effort of “keep informed” as being the capacity to follow the foremost publications and go deep in those that grasp you more. It’s virtually impossible to read and understand all the works that are published. What it’s possible, in theory, is reading the paper abstract with a title that raises your attention (by the problem or by the algorithms/techniques/technologies). In the cases that the interest remains, you can perform a skimming. In a scientific publication, skimming implies the (dynamic) reading of the introduction and the conclusion. If the appeal persists once more, it’s time to put the paper in the list of works that need to be entirely read and studied.
Below, some tools that I use for the goal of following the state of art in AI and related fields. Some of them can be used in any science field, but others are specific.
arXiv
arXiv (spelling “archive”) is an open e-print repository of various areas of science. Currently, the platform gathers together academic works from Physics, Math, Computer Science, Quantitative Biology, Quantitative Finances, Statistics, Electrical Engineering, and Economics. But what is an e-print? E-prints are papers that weren’t peer-reviewed yet, as it happens in a traditional scientific journal. However, a team of moderators in each field is responsible for a primary revision to categorize and remove non-scientific publications. Eventually, most of these papers will be reviewed and published in an academic journal. Moreover, the e-prints are endorsed on the platform itself. Nevertheless, some seminal and influent papers were published only on arXiv.
Each of the major fields is divided into a far number of subfields. Below, you can check the available ones in Computer Science.

A controversial aspect of arXiv is the vast number of submitted papers daily. Following all of these publications is practically unfeasible. Then, we can use a few shortcuts to access the ones that are supposed to be more significant. That is precisely the job made by arXiv Sanity (suggestive name, by the way). Based on feedback from the users, arXiv Sanity is capable of bolding the most rated papers, other than showing images and abstracts in a friendly fashion. This platform’s author video contains the explanation of a few more features. It’s important to note that arXiv Sanity is focused only on AI and Data Science.
DeepAI
Here we have more straightforward stuff. DeepAI is an aggregator of influent papers and news from traditional media when it comes to Artificial Intelligence. As can be seen in the figure below, the website shows news and academic works that were highlighted in recent days.
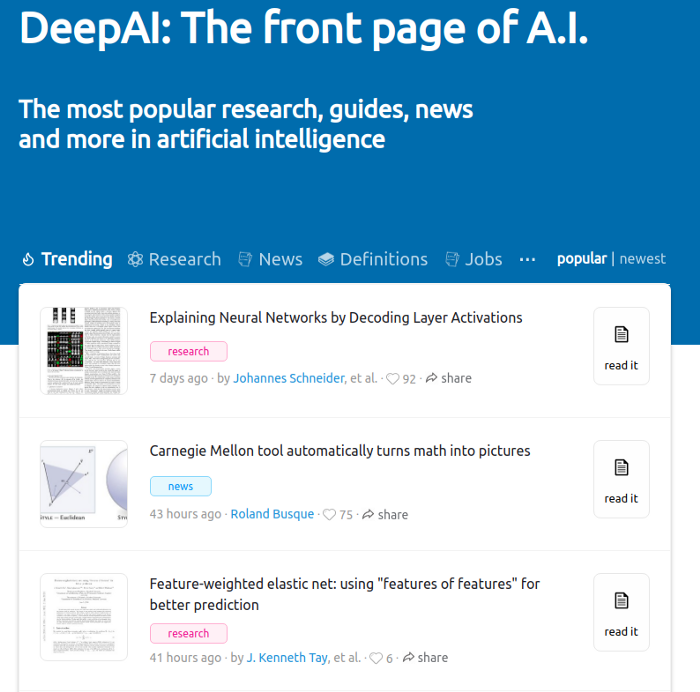
The definitions tab is a section that I consider quite important. There, it’s possible to find concise explanations about relevant topics in AI, like Bayes Theorem and the basics from Neural Networks.
Papers with Code
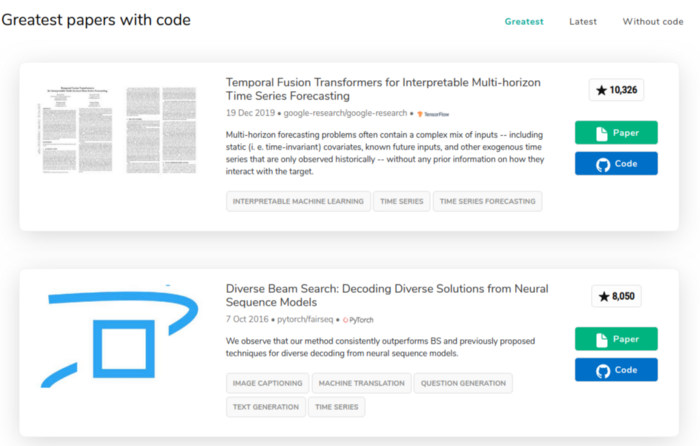
The name Papers with Code is suggestive. Also, from the feedback of users, the website indicates papers in various fields of Data Science (additional topics as well), preferably with available source code and dataset. The platform aggregates performance scores of some solutions to a given problem. Below, two works from the section “time series”.
Mendeley
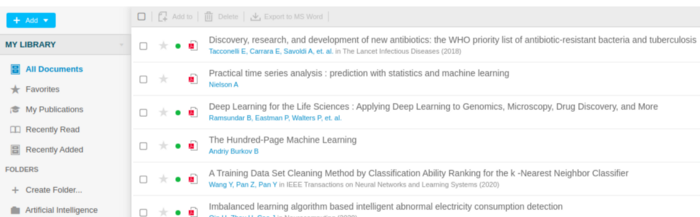
I consider Mendeley a social network for academic researchers. As long as other features, the platform includes profile creation, a list of published papers, research groups, and a list of related job positions. It’s important to note the suggestion tab. When a user adds a bunch of papers (in PDF format) in his/her library section, as an own reading repository, the platform suggests similar works. I have used Mendeley to organize my reading stack. You can do that on the web as well as a mobile app. Below, the current status of my library.
By the way, follow me there.
Scientific Journals
PFinally, if you are used to the academic language and modus operandi, maybe it worth visiting the academic journals sites. Here things are a little bit tricky to organize since the number of estimated publications is high and diverse. But once in a while, it would be great to take a look at it. Usually, I visit IEEE Transactions on Neural Networks and Learning Systems and Learning Systems and Neurocomputing. There were plenty of them, so it depends on your preferences. If it’s an important paper, it will probably pop up on the previously presented platforms. Note that you have to get access to this kind of content (maybe using a university network).
Conclusion
This post aimed at suggesting means and platforms to follow the main and most recent advances in Artificial Intelligence and Data Science. Many times I can’t follow this huge amount of information, however, these are the methods that I use to keep informed. Do you know more sites like these? Share with us!