(Você pode ler esse post em português)
In Data Science, which process should one use? From one or more data sources, how can one extract hidden patterns and build predictive models? Despite the Data Science term being somewhat new, Computer Science has already been concerned with this kind of problem for decades. An academic work especially critical in this field was the paper published by Fayyad et al., in 1996: “From Data Mining to Knowledge Discovery in Databases” [1]. The authors initiated the process known as Knowledge Discovery in Databases (KDD), as one can see in the figure below:
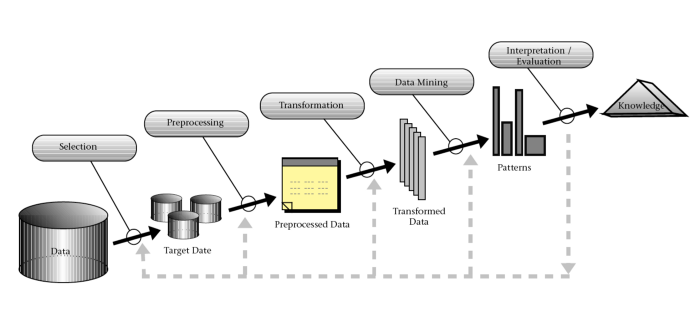
As shown in the figure, KDD is composed of five steps:
Selection: from a business perspective, the data is selected from one or more data sources.
Preprocessing: The data is sanitized thought data cleaning, inconsistencies removal, missing data handling, etc.
Transformation: The data is transformed according to the previous step, where the hidden patterns are really extracted. For instance, this step can include dimensionality reduction and coding changes.
Data Mining: After data preprocessing and transformation, we build predictive or summarization models from Machine Learning or Statistics. In this step, we can find hidden and valuables patterns.
Interpretation/Evaluation: In this step, we evaluate and interpret the hidden patterns and the intelligent models, usually thought a partnership with specialists on the domain and the customer.
It’s important to note that one of the steps from KDD is a widely known term in IT: data mining. Through the years, data mining has been mistaken with the whole KDD process, when, in fact, it’s just a particular step. It’s also intriguing how the terms need to be reinvented from time to time in a dynamic field like Computer Science. If Data Mining today sounds a bit old to our ears, its idea doesn’t differ much from the more modern terms like Data Science or Analytics.
KDD offers an intuitive and general vision of the knowledge extraction scenario. Nevertheless, the process promotes a false idea about its linearity. For instance, usually the selection and the preprocessing steps come together. For data mining, it’s crucial that data had been properly transformed.
In this way, we can understand the reasons behind the creation of another related process, called CRISP-DM (CRoss-Industry Standard Process for Data Mining). CRISP-DM also emerged in 1996 as an open process of knowledge extraction in data, proposed by a consortium initially composed of five large companies [2]. As one can see in the figure below, CRISP-DM indicates in a proper way how the different steps are related to each other.
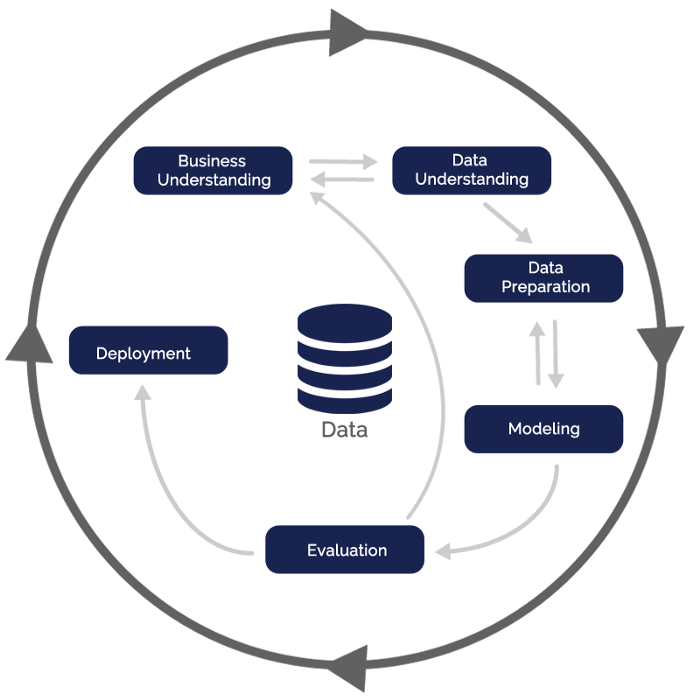
Beyond including feedback cycles in the various steps, CRISP-DM differs from KDD mainly in two aspects. First, there is a clear step in the key stage of business understanding. Questions are made and the customers explain their needs. The process transits between business understanding and data understanding. This indicates that the importance of the customer is crucial. When the model is finally built and evaluated, the activities can come back to the initial step, always trying to reach the desired performance.
An additional perspective given by CRISP-DM it’s the presence of a deployment step. In this step, the domain specialists and the customer evaluate the build model and the solution is finally incorporated in a decision support system. The data analysis becomes, then, in software engineering.
To wrap up, both KDD and CRISP-DM can be used as a guide for the process of knowledge extraction in databases. However, CRISP-DM appears to be more complete and makes clear the flexibility of the steps in favor of the final solution..
[1] https://www.aaai.org/ojs/index.php/aimagazine/article/viewFile/1230/1131, acessed in 09/12/2020
[2] https://en.wikipedia.org/wiki/Cross-industry_standard_process_for_data_mining, acessed in 09/12/2020